2026
ECCV’26
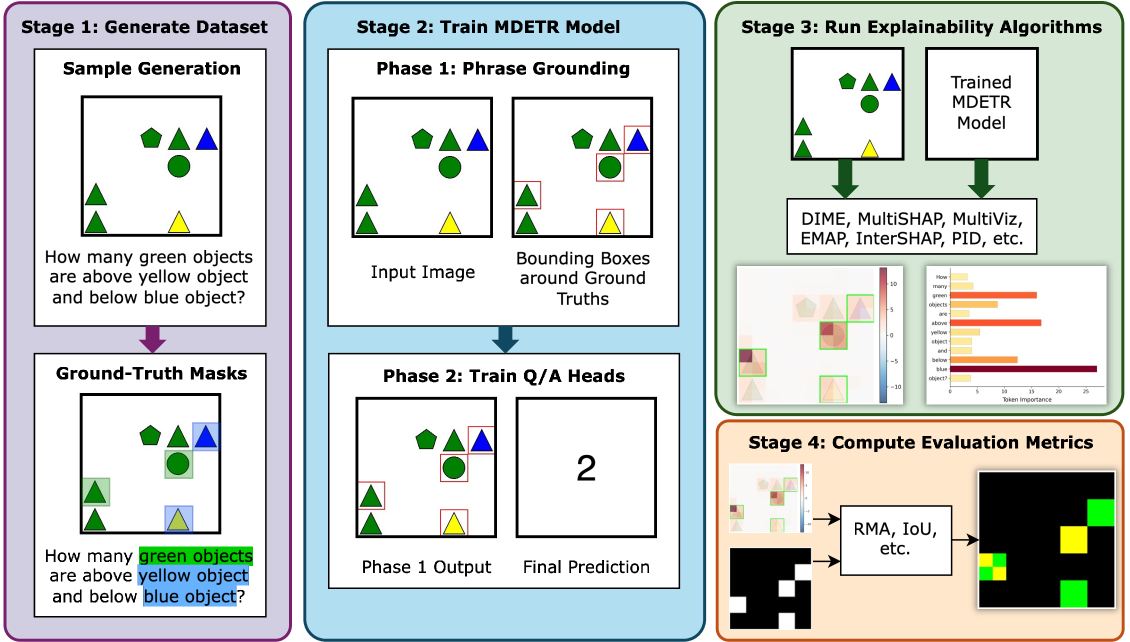
GridVQA-X: A Framework for Evaluating Multimodal Explainability Methods
ECCV 2026
arxiv’26
arxiv’26
arxiv’26
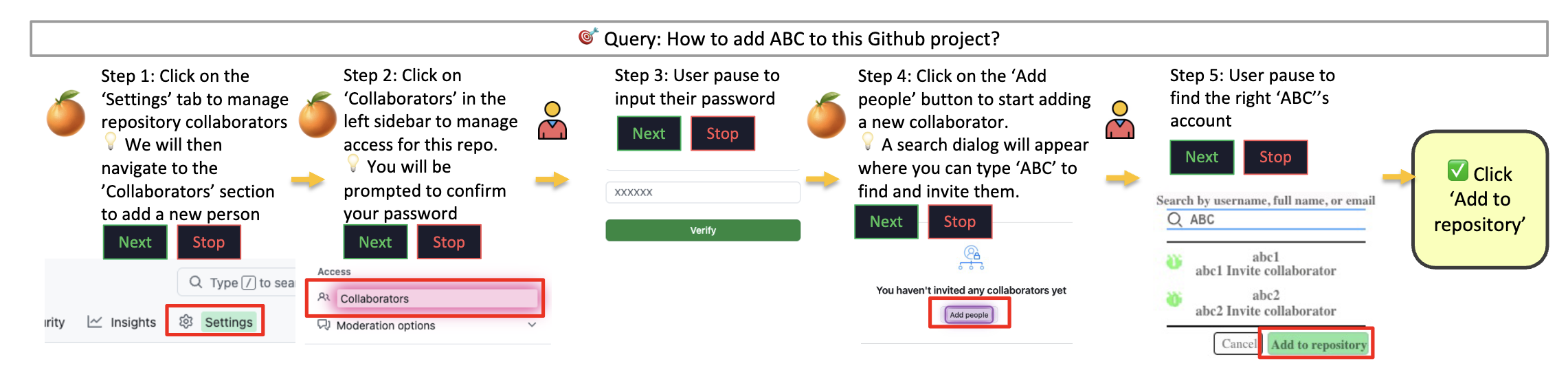
PageGuide: Browser extension to assist users in navigating a webpage and locating information
arXiv, 2026
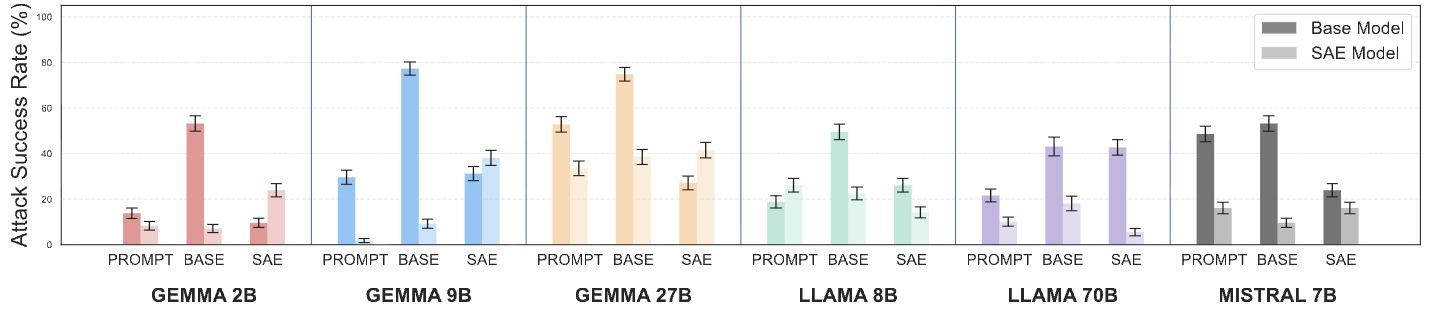
ACL’26

Climate Informatics’26 Oral 🏆
SynopticBench: Evaluating Vision-Language Models on Generating Weather Forecast Discussions of the Future
Climate Informatics 2026 — Oral Presentation
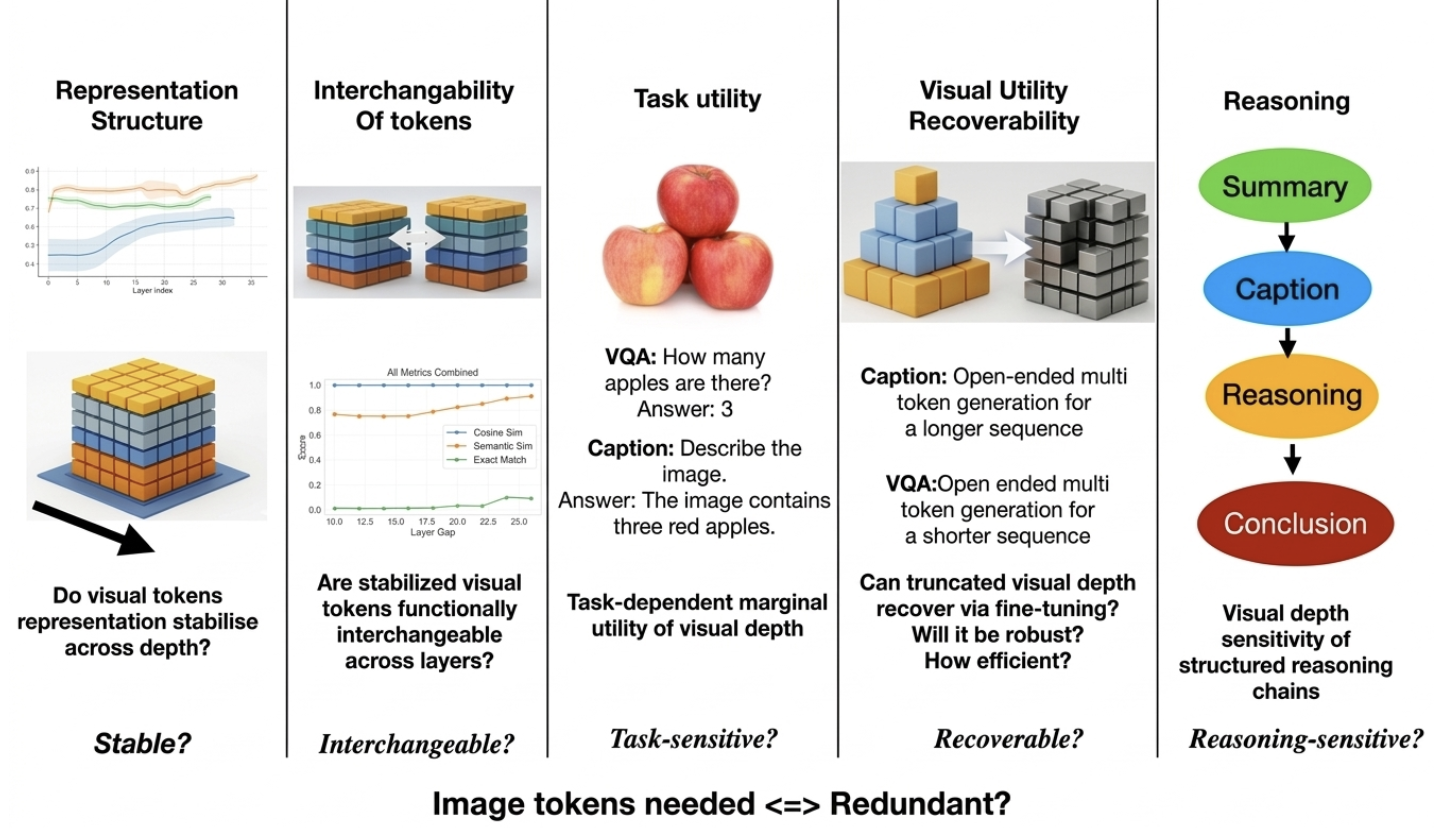
TRUE-V Workshop CVPR’26 Oral 🏆
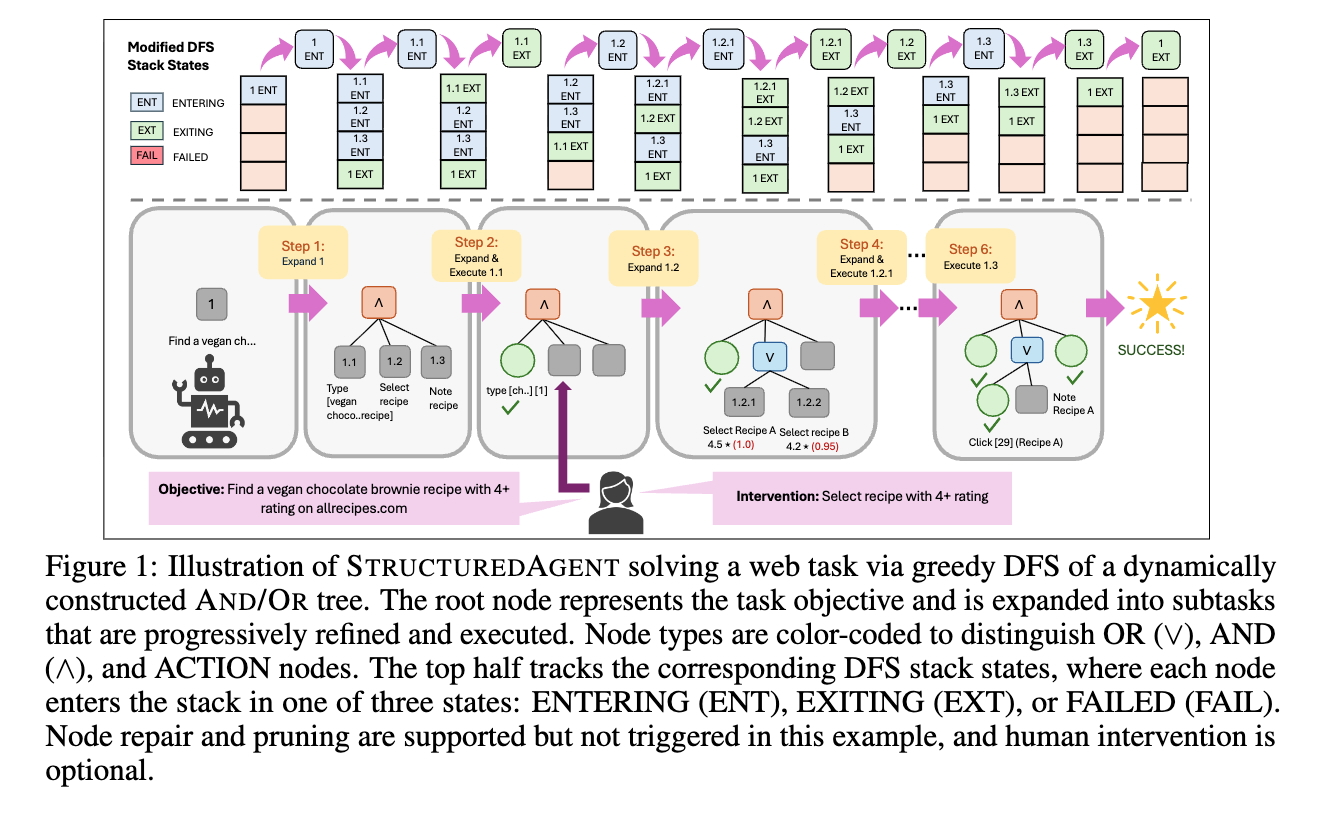
arxiv’26
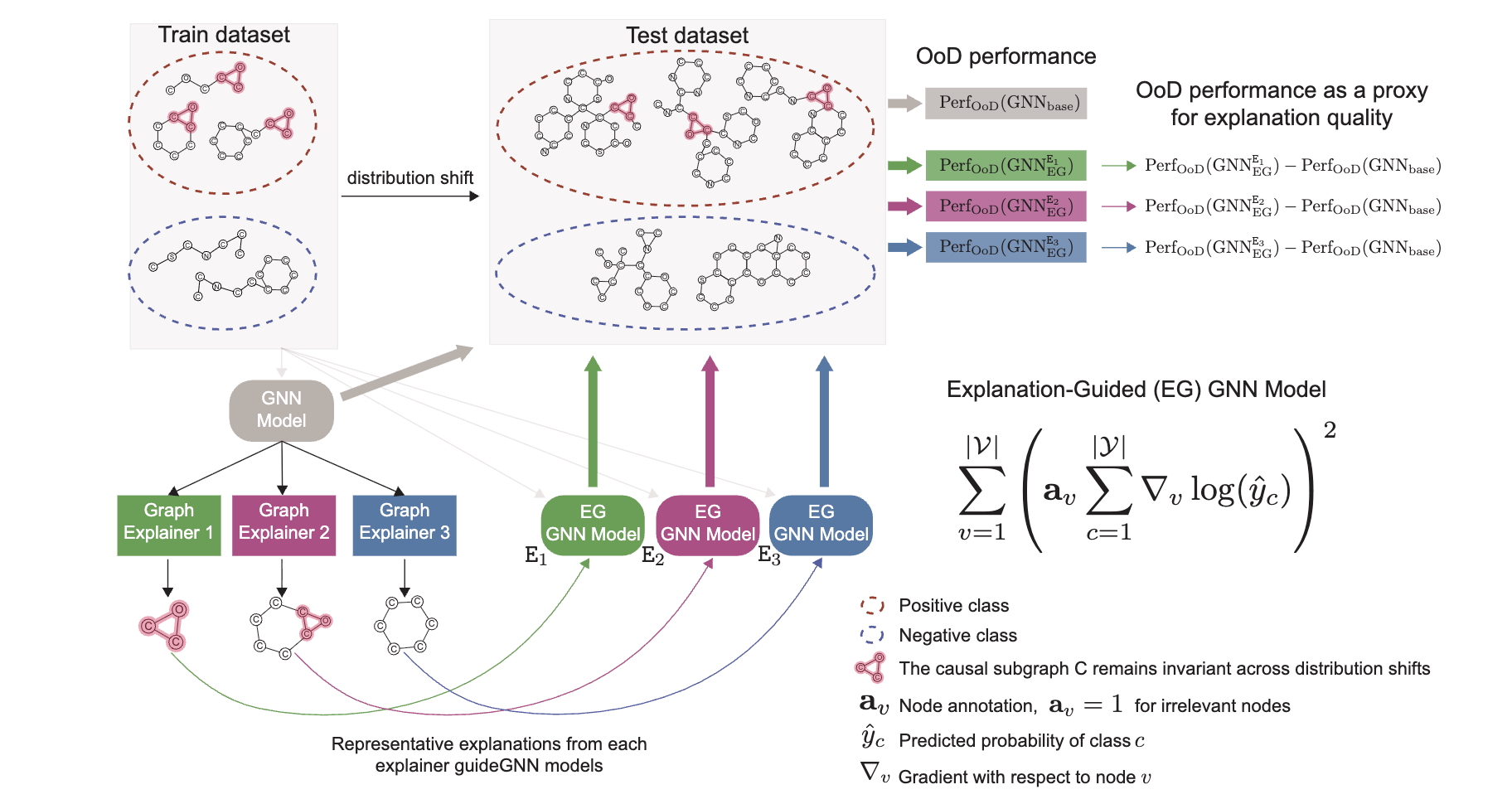
arxiv’26
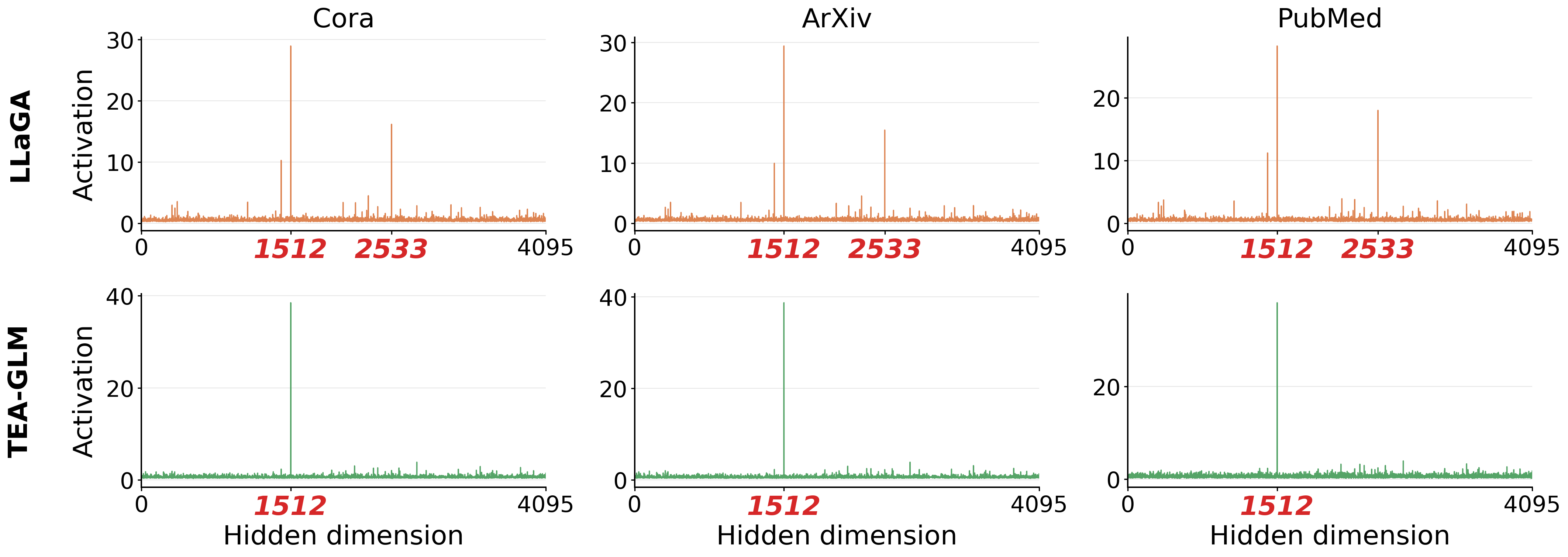
Quantifying Explanation Quality in Graph Neural Networks using Out-of-Distribution Generalization
arxiv, 2026

ACL’26 Oral 🏆
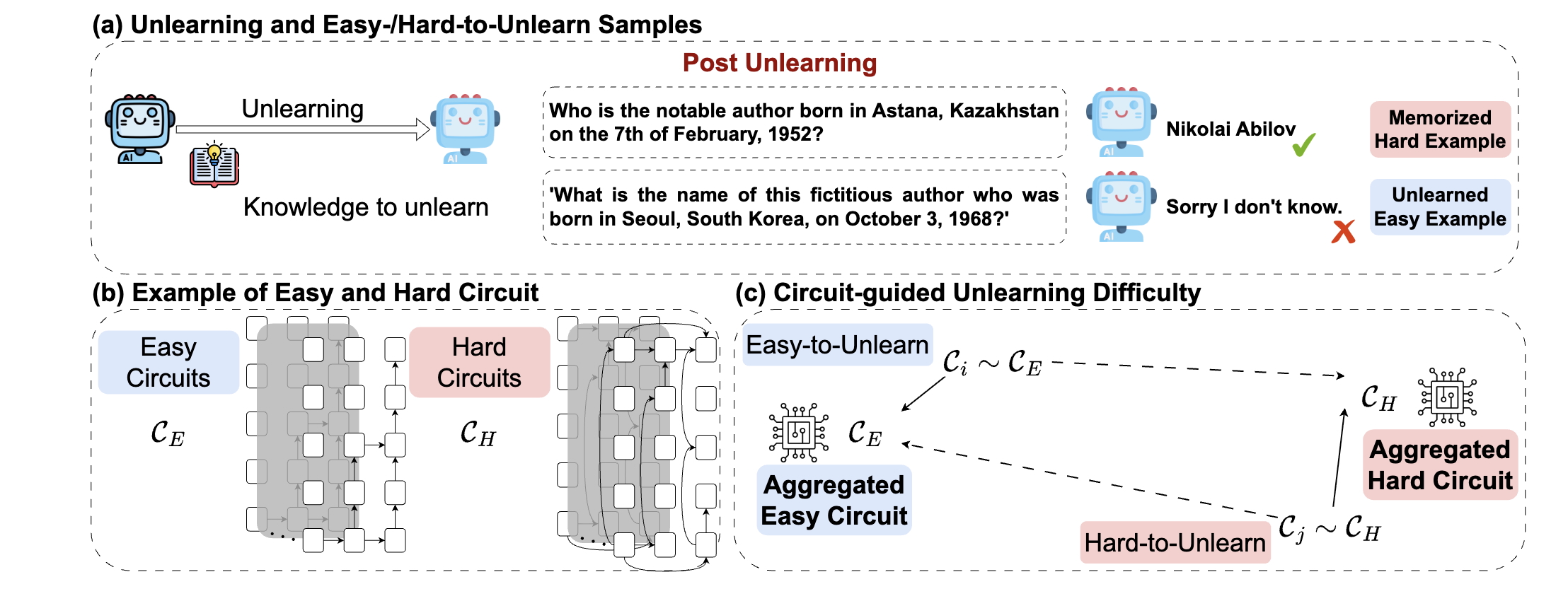
ACL’26
Towards Understanding Unlearning Difficulty: A Mechanistic Perspective and Circuit-Guided Difficulty Metric
ACL 2026

ICML’26
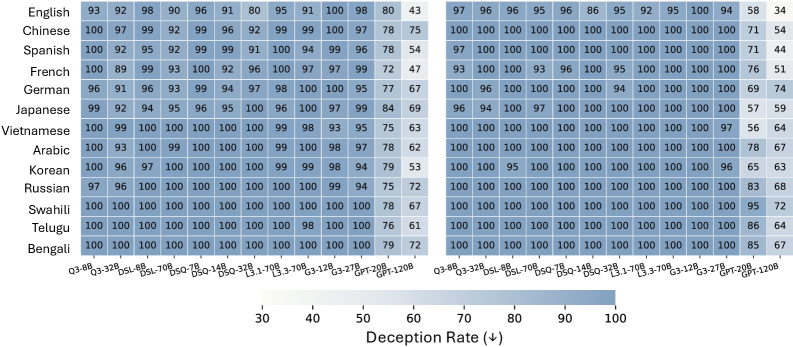
CLINIC: Evaluating Multilingual Trustworthiness in Language Models for Healthcare
ICML 2026

AAAI’26 Oral 🏆

IUI’26
Improving Human Verification of LLM Reasoning through Interactive Explanation Interfaces
IUI 2026
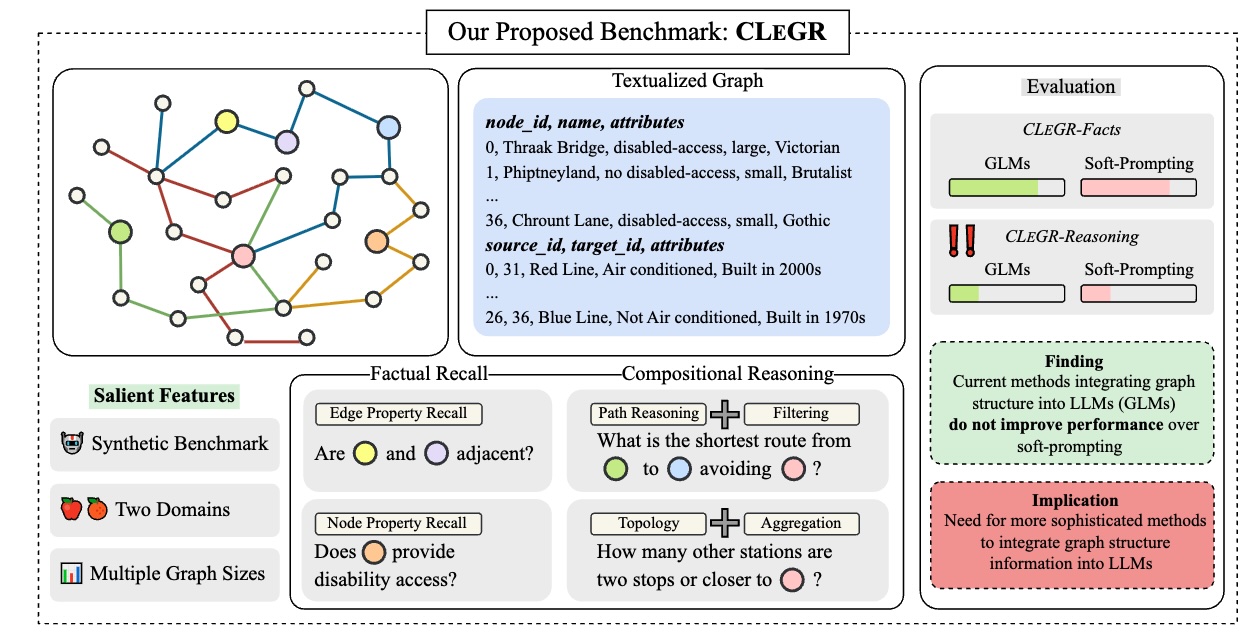
ACL’26
A Graph Talks, But Who’s Listening? Rethinking Evaluations for Graph-Language Models
ACL 2026
2025
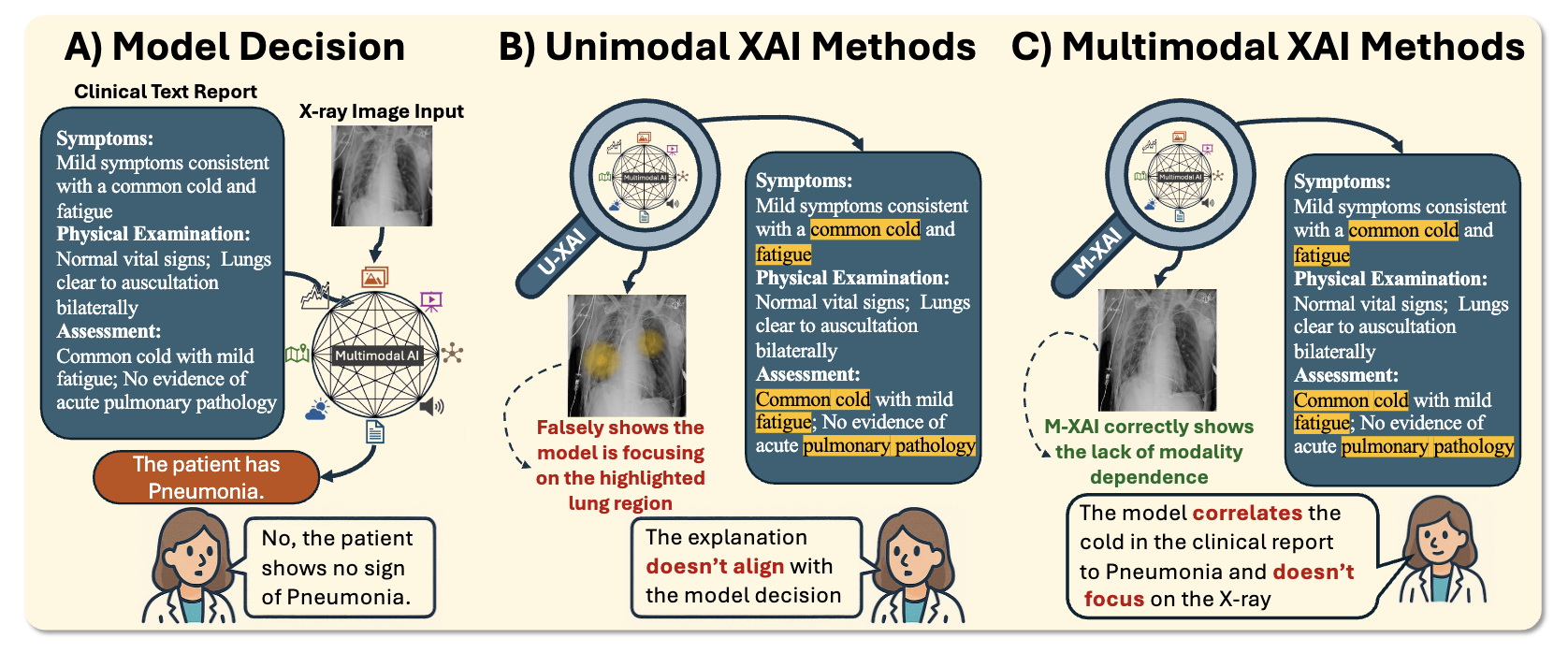
arXiv
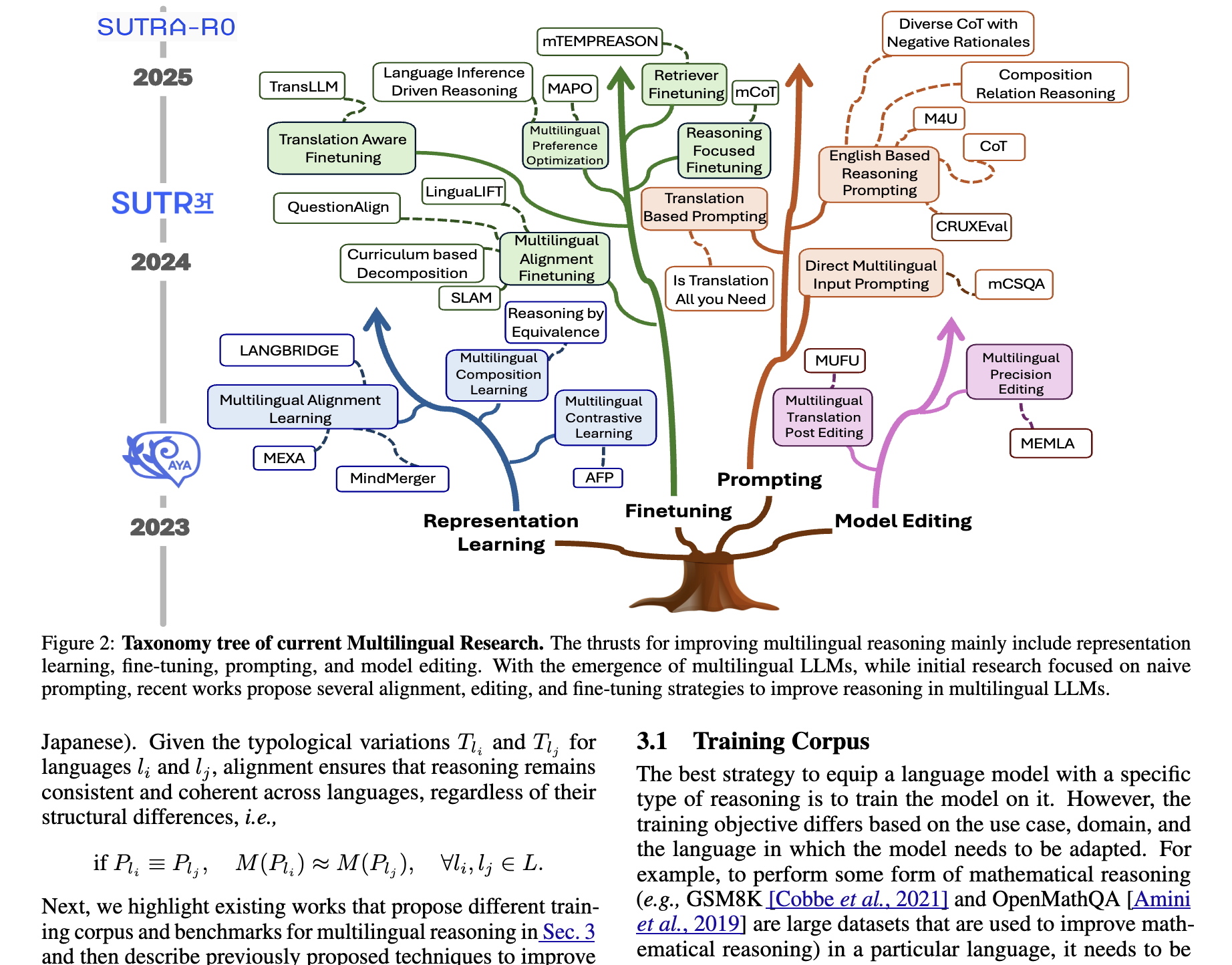
EMNLP'25

EMNLP'25

EMNLP'25
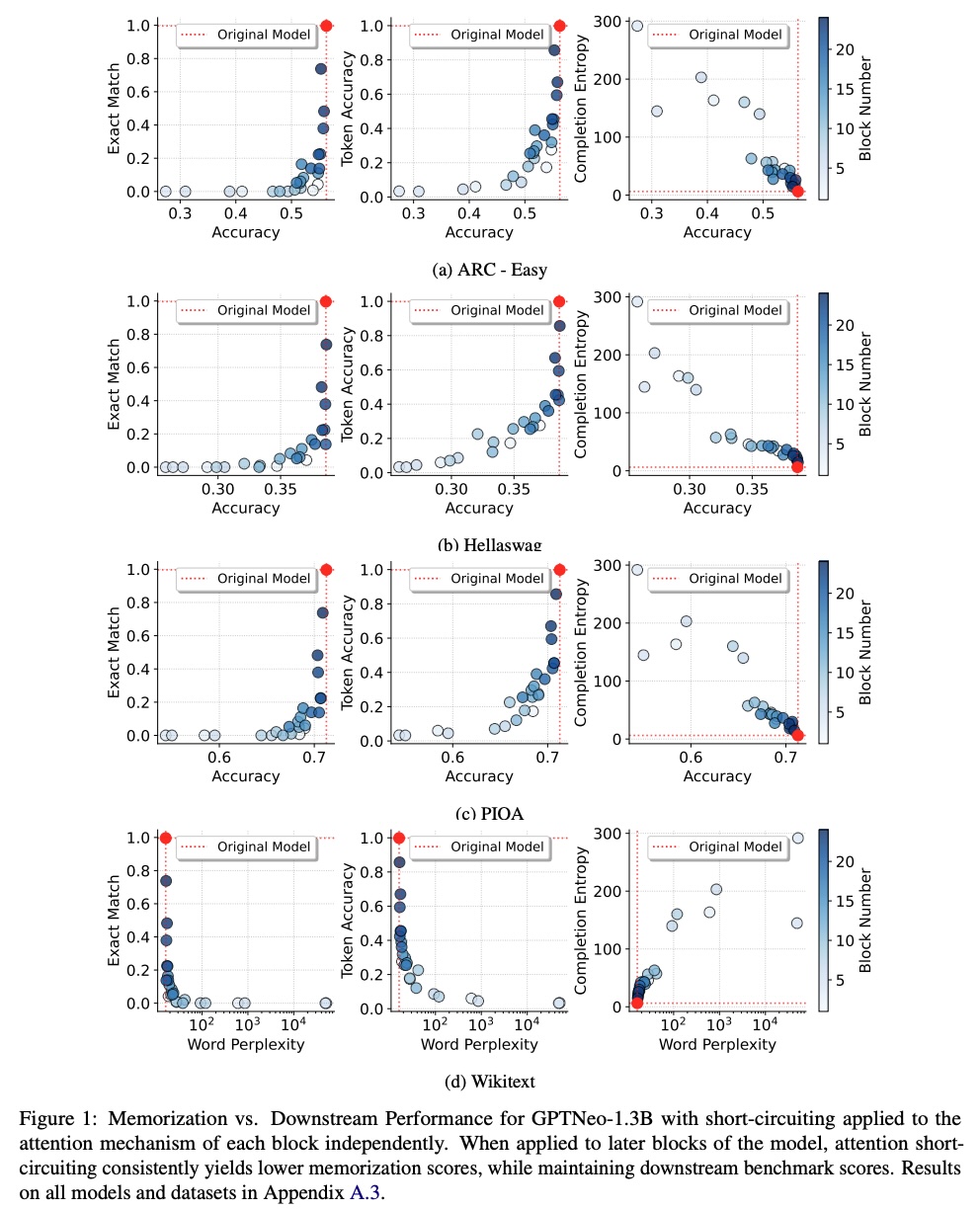
NAACL'25 Oral

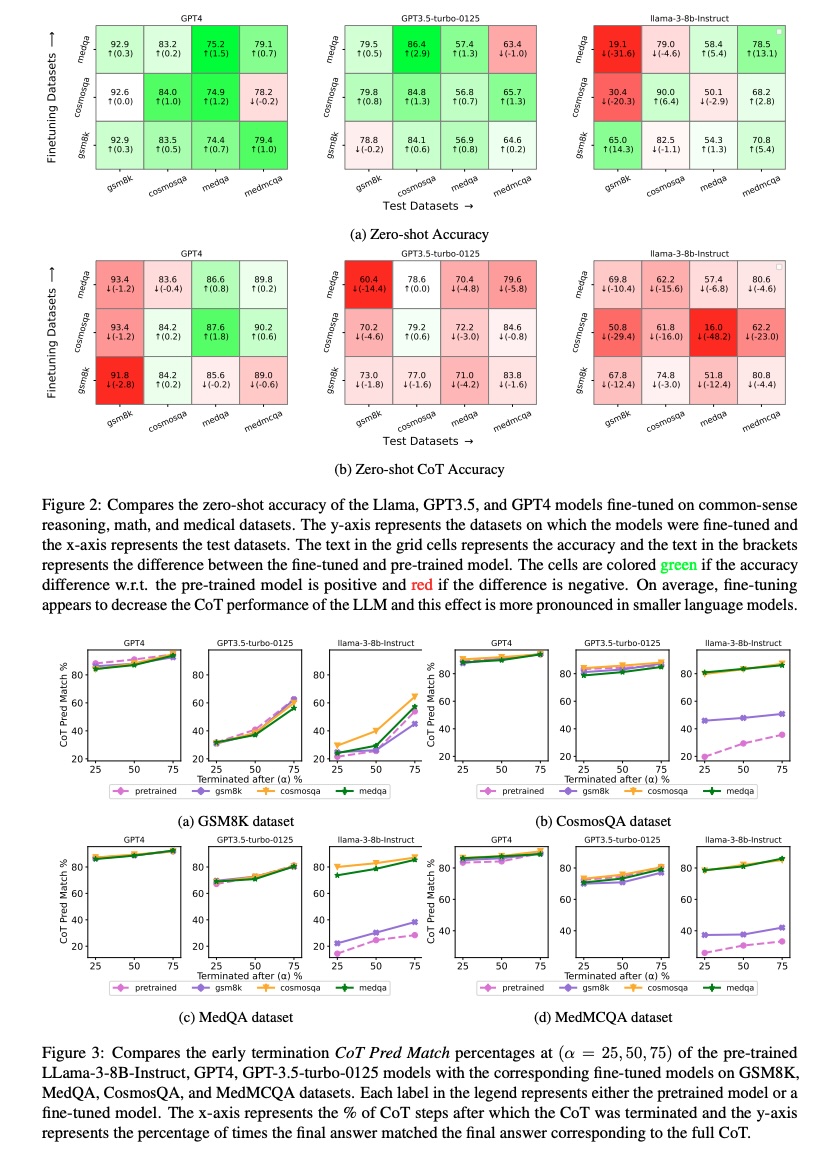
NAACL'25
2024

AISTATS'24 · NeurIPS Spotlight


ICML'24

2022 – 2023 · Selected

NeurIPS'22
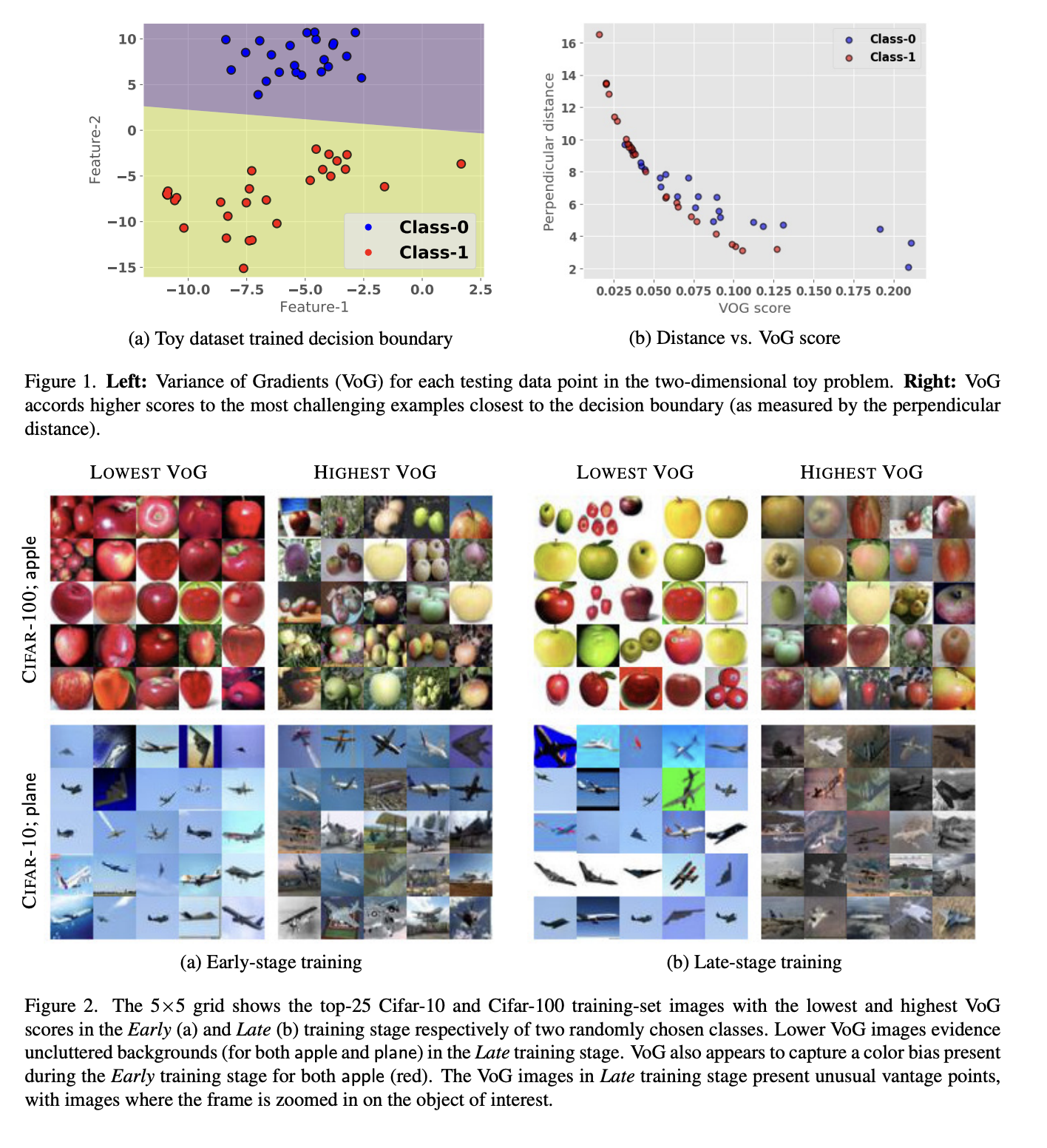
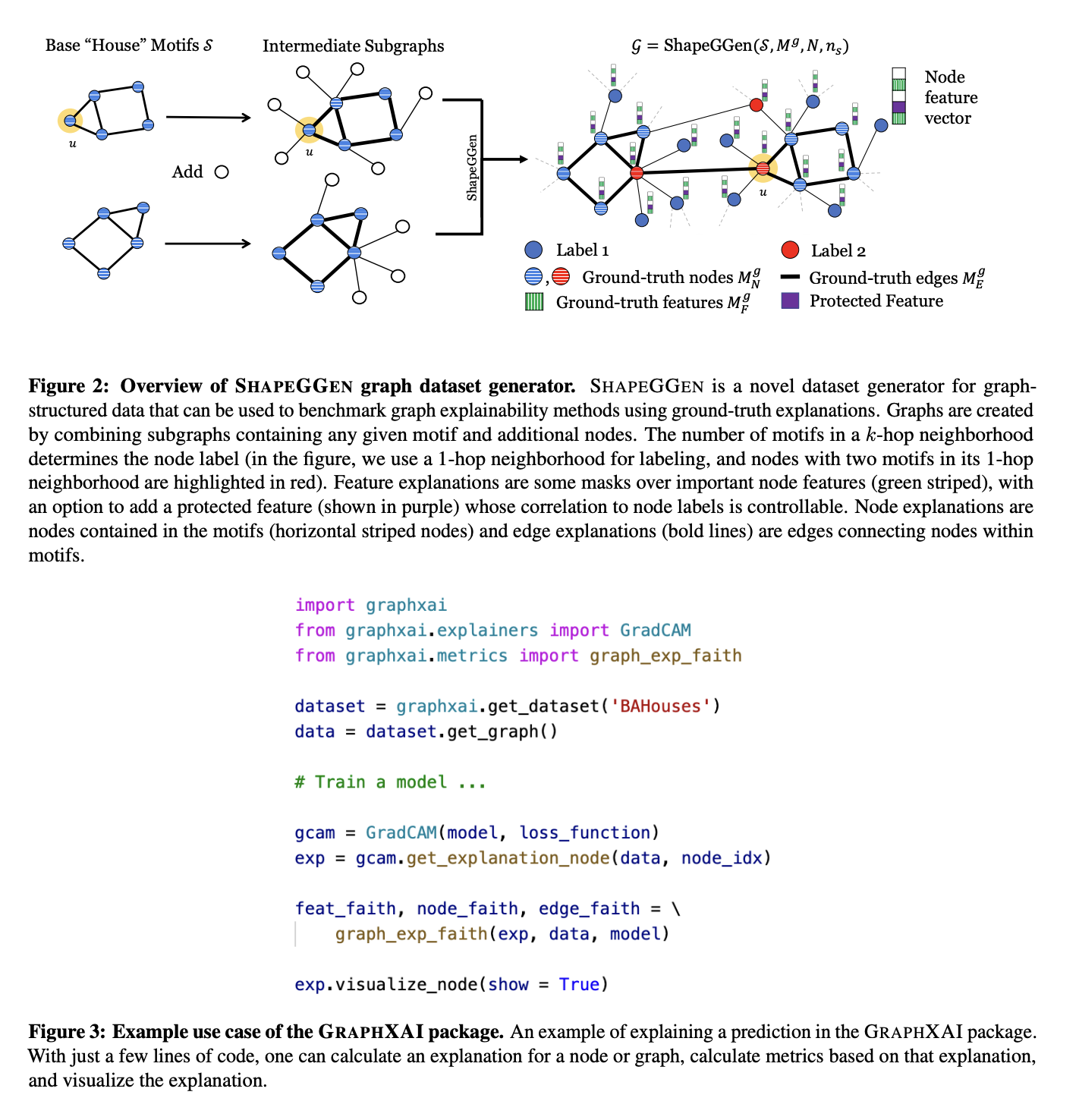
Nature'23
CVPR'23


