Explainable AI
Making AI decisions transparent, interpretable, and actionable for real stakeholders — from concept-level explanations to interpretability agents. Our work spans concept explanations, mechanistic interpretability, model inspection, and interactive explanation interfaces across unimodal and multimodal systems.
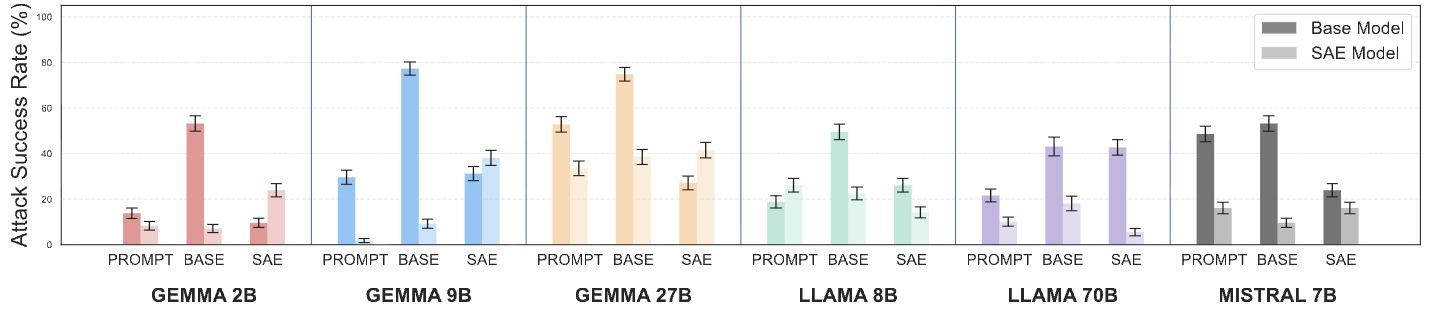
Our work investigates why LLM-generated explanations often appear plausible to humans but may fail to accurately reflect the model's decision-making process. By analyzing the trade-offs between faithfulness and plausibility, our work proposes strategies to improve explanation quality. Our studies have been cited in the OpenAI o1 System Card and reveal fundamental limitations of current approaches in guaranteeing accurate reasoning paths.
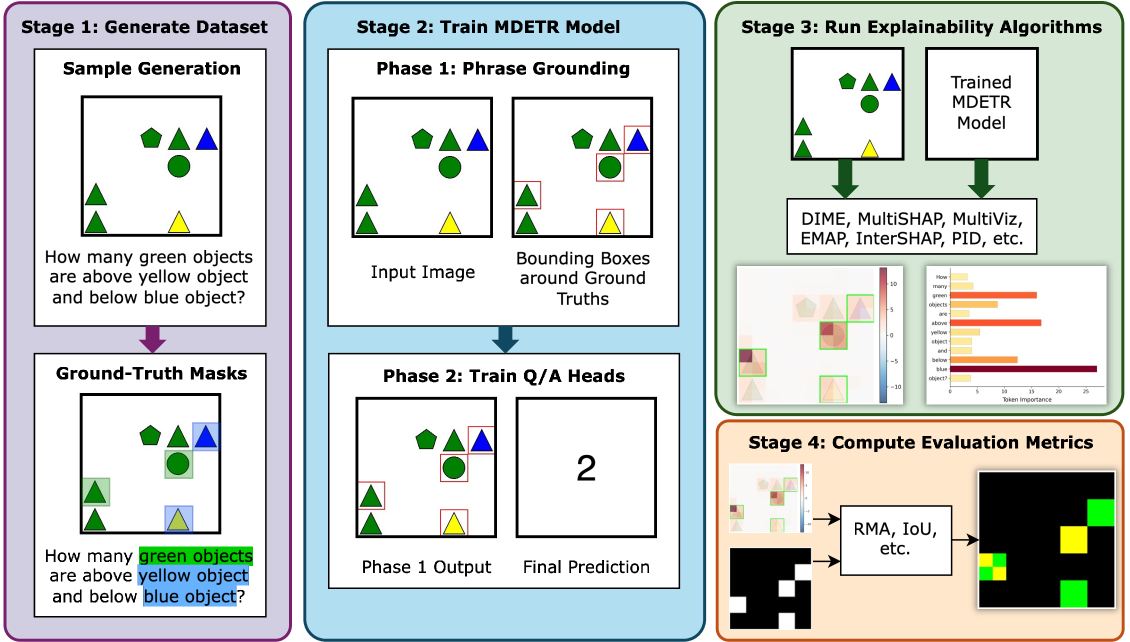
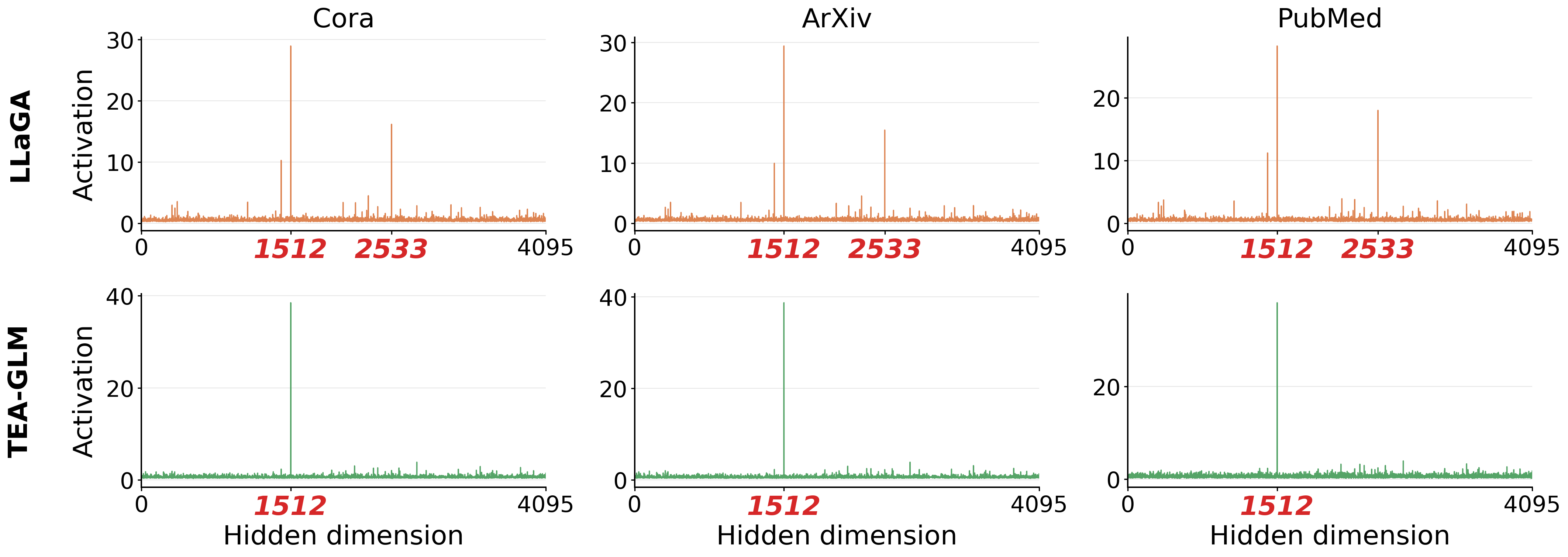
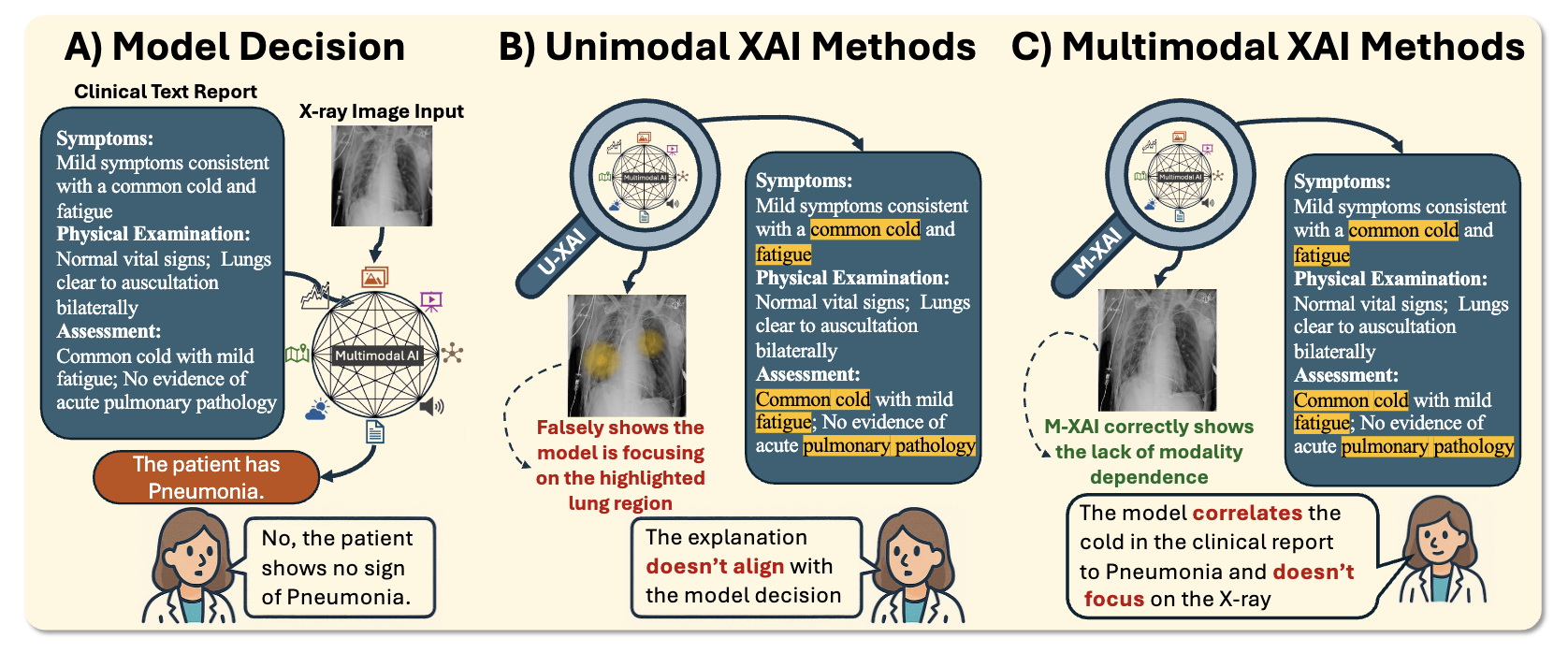
A central thrust of our current work is multimodal explainability. We introduced GridVQA-X (ECCV'26), a controlled benchmark for evaluating whether multimodal explanation methods capture genuine cross-modal reasoning or exploit spurious shortcuts. Complementing this, our mechanistic analysis of Graph Language Models (When Graph Tokens Sink) reveals how graph information is actually encoded and routed inside LLM attention layers — showing that token saliency does not imply information carriage. Together with our survey Rethinking Explainability in the Era of Multimodal AI, these works chart a new evaluation paradigm for XAI in the frontier-model era.